Chapter 2 (Hindi)
| Site: | AssessmentKaro |
| Course: | Operating Systems |
| Book: | Chapter 2 (Hindi) |
| Printed by: | Guest user |
| Date: | Saturday, 18 July 2026, 4:52 PM |
Description
 Topic wise chapter Hindi
Topic wise chapter Hindi
1. Process concept
Process क्या है?
Process एक ऐसा program होता है जो execution में होता है।
उदाहरण के लिए, जब हम C या C++ में program लिखते हैं और उसे compile करते हैं, तो compiler binary code बनाता है। Original code और binary code दोनों ही programs होते हैं, लेकिन जब हम उस binary code को run करते हैं, तब वह एक process बन जाता है।
Process vs Program
- Process एक active entity होता है।
- जबकि program एक passive entity होता है।
Multiple Processes
एक ही program से कई processes बन सकते हैं।
उदाहरण के लिए, जब हम किसी .exe या binary file को कई बार open करते हैं, तो हर बार एक नया instance शुरू होता है, यानी multiple processes create होते हैं।
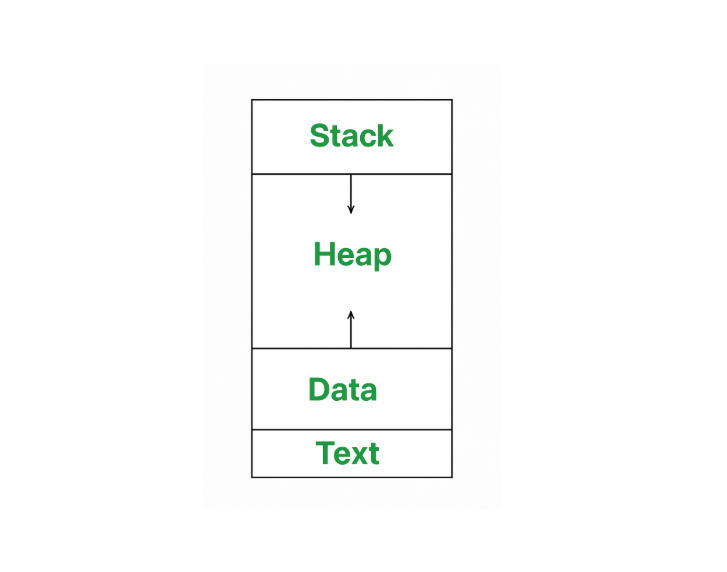
Process Memory Representation
Memory में एक process कई अलग-अलग sections में divide होता है, और हर section का अपना अलग purpose होता है।
👉 एक process memory में सामान्यतः इस प्रकार दिखाई देता है:
- Code Section (Text Section) → इसमें program का actual code store होता है।
- Data Section → इसमें global और static variables store होते हैं।
- Heap → dynamic memory allocation के लिए उपयोग होता है।
- Stack → function calls, local variables और execution context को store करता है।
-
Process Memory Sections
1. Text Section
Text Section (या code segment) में executable instructions होते हैं।
यह आमतौर पर read-only section होता है।
2. Stack
Stack में temporary data store होता है, जैसे:
- function parameters
- return addresses
- local variables
3. Data Section
Data Section में global variables store होते हैं।
4. Heap Section
Heap Section में runtime के दौरान process को dynamically memory allocate की जाती है।
Attributes of a Process
एक process के कई महत्वपूर्ण attributes होते हैं जो Operating System को उसे manage और control करने में मदद करते हैं।
ये सभी attributes एक structure में store होते हैं जिसे Process Control Block (PCB) या task control block कहा जाता है।
PCB में stored मुख्य जानकारी
1. Process ID (PID)
हर process को एक unique number दिया जाता है जिसे PID कहते हैं, जिससे OS उसे पहचान सके।
2. Process State
यह process की current स्थिति दिखाता है, जैसे:
- running
- waiting
- ready
3. Priority & CPU Scheduling Information
यह data OS को यह तय करने में मदद करता है कि अगला process कौन सा run होगा, जैसे:
- priority level
- scheduling queues के pointers
4. I/O Information
इसमें उन input/output devices की जानकारी होती है जिन्हें process उपयोग कर रहा है।
5. File Descriptors
यह open files और network connections की जानकारी रखता है।
6. Accounting Information
यह process के run होने का समय, CPU time usage और अन्य resource usage को track करता है।
7. Memory Management Information
इसमें process को allocate की गई memory की पूरी जानकारी होती है, जैसे:
- memory location
- memory layout (stack, heap आदि)
2. Operations on processes
Process Operations
Process operations से मतलब उन actions या activities से है जो Operating System में processes पर perform किए जाते हैं।
इन operations में शामिल हैं:
- creating
- terminating
- suspending
- resuming
- processes के बीच communication
ये operations programs के execution को manage और control करने के लिए बहुत महत्वपूर्ण होते हैं।
Importance of Process Operations
Processes पर होने वाले operations Operating System के सही functioning के लिए आवश्यक होते हैं। ये program execution के flow और resource allocation को efficiently manage करने में मदद करते हैं।
Process का lifecycle कई महत्वपूर्ण operations से मिलकर बना होता है:
- creation
- scheduling
- blocking
- preemption
- termination
इन सभी operations का अपना महत्वपूर्ण role होता है, जो multitasking और optimal resource utilization को सुनिश्चित करता है।
What is a Process?
Process एक program के execution की activity होती है।
अर्थात, यह एक program under execution होता है।
हर process को अपना task पूरा करने के लिए कुछ resources की आवश्यकता होती है।
- Processes वे programs होते हैं जो ready state से dispatch होकर CPU में schedule किए जाते हैं execution के लिए।
- PCB (Process Control Block) process का context store करता है।
- एक process अन्य processes भी create कर सकता है, जिन्हें child processes कहा जाता है।
- Process को terminate होने में समय लग सकता है और यह isolated होता है, यानी यह अपनी memory किसी अन्य process के साथ share नहीं करता।
Process States
एक process के निम्नलिखित states हो सकते हैं:
- New
- Ready
- Running
- Waiting
- Terminated
- Suspended
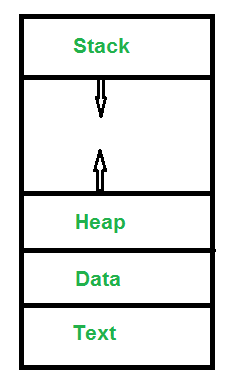
Process Memory Sections
1. Text
Text Section (या code segment) में process की current activity होती है, जिसे Program Counter के value द्वारा represent किया जाता है। इसमें executable instructions शामिल होते हैं।
2. Stack
Stack में temporary data store होता है, जैसे:
- function parameters
- return addresses
- local variables
3. Data
Data Section में global variables store होते हैं।
4. Heap
Heap में runtime के दौरान process को dynamically memory allocate की जाती है।
Operation on a Process
एक process का execution एक complex activity होती है, जिसमें कई operations शामिल होते हैं।
Execution के दौरान निम्नलिखित operations perform किए जाते हैं:
- Process Creation
- Process Scheduling
- Process Blocking
- Process Preemption
- Process Termination

Operations on a Process
1. Creation
यह process execution का initial step होता है।
Process creation का मतलब है execution के लिए एक नया process बनाना। यह system, user या किसी existing process द्वारा किया जा सकता है।
कुछ situations जिनमें process create होता है:
- Computer start होने पर system कई background processes create करता है।
- User नया process create करने की request कर सकता है।
- कोई running process खुद एक नया child process create कर सकता है।
- Batch system batch job को initiate करता है।
2. Scheduling / Dispatching
यह वह process है जिसमें process की state ready → running में बदलती है।
- Operating System ready queue से process को उठाकर CPU पर execute करता है।
- Dispatching तब होती है जब resources free हों या process की priority ज्यादा हो।
- कभी-कभी running process को हटाकर (preempt करके) ready process को run कराया जाता है।
3. Blocking
जब process कोई input-output (I/O) system call करता है, तो वह wait करने लगता है और OS उसे blocked state में डाल देता है।
- Process I/O completion का इंतजार करता है।
- OS उस process को block करके CPU पर किसी अन्य process को dispatch कर देता है।
- इस स्थिति में process waiting state में होता है।
4. Preemption
जब किसी process का allotted time (time slice) खत्म हो जाता है या कोई high priority process आ जाता है, तो OS current process को रोक देता है।
- यह तभी संभव है जब CPU scheduling preemption को support करता हो।
- Priority scheduling में high priority process आने पर current process को हटा दिया जाता है।
- OS उस process को वापस ready state में भेज देता है।
5. Process Termination
Process termination का मतलब process को समाप्त करना है।
इसमें process द्वारा उपयोग किए गए resources को release कर दिया जाता है।
Termination के कारण:
- Process अपना execution पूरा कर लेता है और OS को inform करता है।
- Operating System किसी error के कारण process को terminate कर देता है।
- Hardware problem के कारण भी process terminate हो सकता है।
3. CPU Scheduling
CPU Scheduling
CPU scheduling वह process है जिसका उपयोग Operating System (OS) यह तय करने के लिए करता है कि किस process को किसी particular time पर CPU मिलेगा।
यह जरूरी है क्योंकि CPU एक समय में केवल एक ही task execute कर सकता है, जबकि कई processes execute होने के लिए ready रहते हैं।
CPU Scheduling के उद्देश्य
- CPU utilization को maximize करना
- Process के response time और waiting time को minimize करना
CPU Scheduling की आवश्यकता
CPU scheduling यह तय करता है कि कौन सा process CPU का उपयोग करेगा जब कोई अन्य process suspended हो।
- इसका मुख्य उद्देश्य यह सुनिश्चित करना है कि CPU idle न रहे।
- OS हमेशा ready queue में से किसी एक process को select करता है ताकि CPU busy रहे।
Terminologies Used in CPU Scheduling
1. Arrival Time
वह समय जब process ready queue में आता है।
2. Completion Time
वह समय जब process अपना execution पूरा करता है।
3. Burst Time
CPU execution के लिए process को जितना समय चाहिए उसे burst time कहते हैं।
4. Turn Around Time (TAT)
Process के complete होने में लगा कुल समय।
👉 Formula:
Turn Around Time = Completion Time – Arrival Time
5. Waiting Time (W.T)
Process के wait करने का समय (ready queue में)।
👉 Formula:
Waiting Time = Turn Around Time – Burst Time
CPU Scheduling Algorithm Design करते समय ध्यान देने योग्य बातें
1. CPU Utilization
- CPU को जितना हो सके उतना busy रखना चाहिए।
- Real system में CPU utilization लगभग 40% से 90% के बीच होता है।
2. Throughput
- प्रति unit time में complete होने वाले processes की संख्या को throughput कहते हैं।
- यह process की length पर depend करता है।
3. Turn Around Time
- Process के arrival से लेकर completion तक का समय।
- इसमें waiting, CPU execution और I/O time शामिल होता है।
4. Waiting Time
- Ready queue में process के wait करने का समय।
- Scheduling algorithm मुख्यतः इसी को affect करता है।
5. Response Time
- Process submit होने से लेकर first response मिलने तक का समय।
- यह interactive systems में अधिक महत्वपूर्ण होता है।
Types of CPU Scheduling Algorithms
1. Preemptive Scheduling
इसमें OS running process को बीच में रोककर दूसरे process को CPU दे सकता है।
- Process running → ready state या waiting → ready state में जा सकता है।
- Example: Priority Scheduling, Round Robin
2. Non-Preemptive Scheduling
इसमें process तब तक CPU पर चलता है जब तक वह पूरा execute न हो जाए या waiting state में न चला जाए।
- Process खुद CPU छोड़ता है।
- Example: FCFS, SJF (non-preemptive)
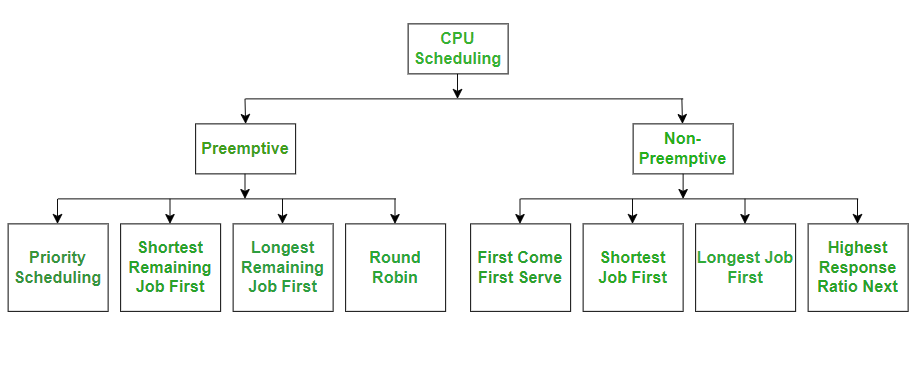
CPU Scheduling Algorithms
अब हम अलग-अलग CPU scheduling algorithms को एक-एक करके समझते हैं:
- FCFS (First Come First Serve)
- SJF (Shortest Job First)
- SRTF (Shortest Remaining Time First)
- Round Robin (RR)
- Priority Scheduling
- HRRN (Highest Response Ratio Next)
- Multilevel Queue (MLQ)
- Multilevel Feedback Queue (MFLQ)
📊 Comparison of CPU Scheduling Algorithms
| Algorithm | Allocation (कैसे CPU मिलता है) | Complexity | Average Waiting Time (AWT) | Preemption | Starvation | Performance |
|---|---|---|---|---|---|---|
| FCFS | Arrival time के अनुसार | Simple और easy | Large (ज्यादा) | No | No | Slow |
| SJF | Lowest Burst Time (BT) के आधार पर | FCFS से ज्यादा complex | FCFS से कम | No | Yes | Best (minimum waiting time) |
| SRTF | Lowest remaining Burst Time (preemptive) | FCFS से ज्यादा complex | Depend करता है | Yes | Yes | Short jobs को preference |
| Round Robin (RR) | Arrival order + fixed Time Quantum (TQ) | TQ पर depend | SJF से ज्यादा | Yes | No | Fair (equal time) |
| Priority (Preemptive) | Highest priority पहले | कम complex | FCFS से कम | Yes | Yes | Good लेकिन starvation |
| Priority (Non-Preemptive) | Priority के अनुसार execution | और कम complex | FCFS से कम | No | Yes | Batch systems के लिए अच्छा |
| MLQ | Multiple queues की priority के अनुसार | Complex | FCFS से कम | No | Yes | Good लेकिन starvation |
| MFLQ | Dynamic priority queues के आधार पर | सबसे ज्यादा complex | सबसे कम (कई cases में) | No | No | Best performance |
4. IPC
Inter Process Communication (IPC)
Inter-Process Communication (IPC)
Inter-Process Communication (IPC) एक mechanism है जो processes को आपस में communicate करने और data share करने की सुविधा देता है जब वे run हो रहे होते हैं।
- हर process का अपना अलग memory space होता है
- इसलिए IPC controlled तरीके से information exchange करने में मदद करता है
- यह processes को efficiently और safely साथ में काम करने में मदद करता है
IPC का उपयोग
- Processes को synchronize करने में मदद करता है
- Information share करने में सहायता करता है
- Shared resources access करते समय conflicts को avoid करता है
IPC के Methods
IPC के मुख्यतः दो methods होते हैं:
1. Shared Memory
2. Message Passing
Operating System दोनों methods को implement कर सकता है।
Example of IPC
एक simple example है Bank ATM system:
- एक process card और PIN read करता है
- दूसरा process account balance check करता है
- तीसरा process cash dispense करता है
👉 ये सभी processes आपस में communicate करके transaction को सही तरीके से complete करते हैं
Shared Memory
Shared Memory में processes एक common memory area share करते हैं।
- Processes एक ही memory location से data read और write करते हैं
- Communication fast होता है क्योंकि direct memory access होता है
- लेकिन synchronization programmer पर depend करता है
Shared Memory के उपयोग
- एक process दूसरे process से data extract कर सकता है
- एक process दूसरे process को information भेज सकता है
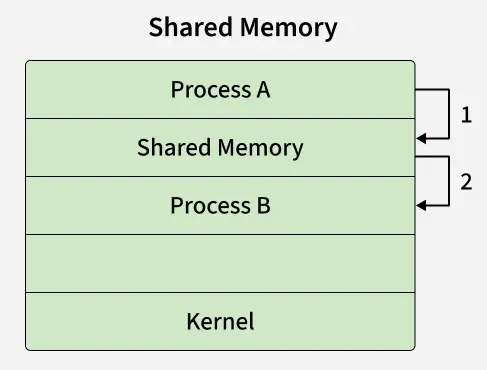
Shared Memory (Detail)
ऊपर दिए गए shared memory model में एक common memory space kernel द्वारा allocate किया जाता है।
- Process A shared memory region में data write करता है (Step 1)
- Process B उसी shared memory से data read करता है (Step 2)
👉 क्योंकि दोनों processes same memory segment को access करते हैं:
- यह method बहुत fast होता है
- लेकिन synchronization की जरूरत होती है (जैसे semaphores) ताकि conflict न हो
Example
जैसे multiple लोग एक ही Google Doc को एक साथ edit करते हैं, वैसे ही processes shared memory का उपयोग करते हैं।
Message Passing
Message Passing एक ऐसा method है जिसमें processes आपस में messages भेजकर और receive करके communicate करते हैं।
- एक process message send करता है
- दूसरा process उसे receive करता है
- इस तरह data exchange होता है
Message Passing के Methods
- Sockets
- Message Queues
- Pipes
Message Passing की विशेषताएँ
- Direct memory share नहीं होती
- Communication controlled और safe होता है
- Synchronization की जरूरत कम होती है (shared memory के मुकाबले)
- थोड़ा slow हो सकता है क्योंकि message transfer होता है
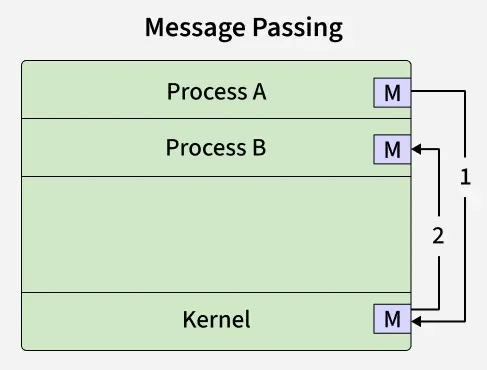
Message Passing (Detail)
ऊपर दिए गए message passing model में processes kernel के माध्यम से messages भेजकर communicate करते हैं।
- Process A kernel को message send करता है (Step 1)
- Kernel उस message को Process B तक deliver करता है (Step 2)
👉 यहाँ processes direct memory share नहीं करते, बल्कि communication system calls जैसे send() और recv() के माध्यम से होता है।
Features
- यह method simple और safe होता है
- Shared data overwrite होने का risk नहीं होता
- लेकिन kernel involvement के कारण थोड़ा overhead बढ़ जाता है
Example
जैसे group chat में message पहले server पर जाता है, फिर सभी users को दिखता है, वैसे ही processes kernel के through message exchange करते हैं।
Problems in Inter-Process Communication (IPC)
जब multiple processes resources share करते हैं, तो कुछ problems हो सकती हैं:
- Race Condition → data inconsistency
- Deadlock → processes indefinitely wait करते हैं
- Starvation → कुछ processes को CPU नहीं मिलता
- Overhead → communication cost बढ़ता है
- Security Issues → unauthorized access का risk
- Scalability Issues → processes बढ़ने पर management कठिन
Classical IPC Problems
1. Dining Philosophers Problem
👉 यह problem deadlock और starvation को explain करता है
- 5 philosophers table पर बैठे होते हैं
- हर philosopher को खाने के लिए 2 forks चाहिए
- अगर सभी एक-एक fork उठा लें → कोई भी नहीं खा पाएगा → deadlock
Solution
- Semaphores या monitors का उपयोग
- एक समय में limited philosophers को खाने देना
- Fork उठाने का proper order define करना
2. Producer–Consumer Problem
👉 यह problem synchronization और buffer management से related है
- Producer data बनाता है
- Consumer data use करता है
- Problem:
- Buffer full होने पर producer wait करे
- Buffer empty होने पर consumer wait करे
Solution
- Mutex for mutual exclusion
- Counting semaphores for buffer slots
- Proper synchronization maintain करना
3. Readers–Writers Problem
👉 यह problem shared data access को control करता है
- Multiple readers एक साथ read कर सकते हैं
- लेकिन writer को exclusive access चाहिए
Solution
- Reader-Writer locks या semaphores
- Multiple readers allowed
- Writer को exclusive access
- Priority rules से starvation avoid करना
4. Sleeping Barber Problem
👉 यह problem process coordination को समझाता है
- Barber सोता है जब कोई customer नहीं होता
- Customer आने पर barber को जगाया जाता है
- Limited chairs होते हैं
Solution
- Semaphores का उपयोग
- Barber idle होने पर sleep करता है
- Customers wait करते हैं (अगर chair available हो)
- System deadlock-free रहता है
5. Process synchronization
Introduction to Process Synchronization
Process Synchronization
Process Synchronization एक mechanism है जो Operating System (OS) में multiple processes के execution को manage करता है, खासकर जब वे shared resources को access करते हैं।
👉 इसका main purpose है:
- Data consistency बनाए रखना
- Race condition को prevent करना
- Deadlock से बचना
Types of Processes (Synchronization के आधार पर)
1. Independent Process
- एक process का execution दूसरे process को affect नहीं करता
- कोई data sharing नहीं होती
2. Cooperative Process
- एक process दूसरे process को affect कर सकता है
- Processes आपस में data share करते हैं
- Synchronization जरूरी होता है
Definition (Simple)
Process Synchronization का मतलब है multiple cooperating processes को इस तरह coordinate करना कि:
- Shared resources का controlled access हो
- Race condition और अन्य problems avoid हों
- System smooth और efficient तरीके से काम करे
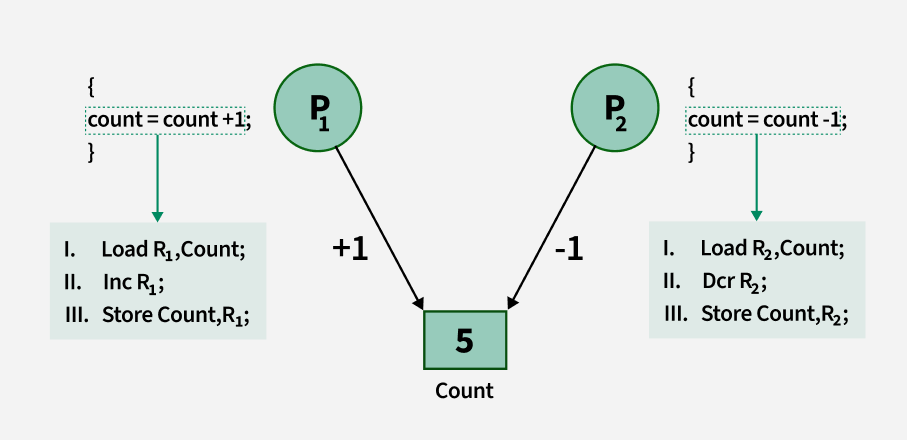
Problems due to Improper Synchronization
अगर Process Synchronization सही तरीके से नहीं किया जाता, तो ये problems होती हैं:
1. Inconsistency
जब दो या अधिक processes एक ही shared data को बिना synchronization के access करते हैं, तो data inconsistent हो जाता है।
👉 एक process का update दूसरे द्वारा overwrite हो सकता है।
2. Loss of Data
जब multiple processes एक ही resource पर write करते हैं:
- Data overwrite हो सकता है
- Important information lost हो सकती है
👉 Result: corrupted या incomplete data
3. Deadlock
जब processes एक-दूसरे के resources का wait करते रहते हैं:
- कोई process आगे नहीं बढ़ पाता
- System hang हो सकता है
Role of Synchronization in IPC
✔ Preventing Race Condition
Processes को एक साथ shared data access करने से रोकता है
✔ Mutual Exclusion
एक समय में केवल एक process critical section में जाता है
✔ Process Coordination
Processes को condition के अनुसार wait/execute करने देता है
✔ Deadlock Prevention
Proper resource allocation से deadlock avoid करता है
✔ Safe Communication
Data/messages सही order में send और receive होते हैं
✔ Fairness
हर process को fair chance मिलता है (no starvation)
Types of Process Synchronization
1. Competitive Synchronization
- Processes shared resource के लिए compete करते हैं
- Synchronization न होने पर:
👉 Inconsistency या Data loss
2. Cooperative Synchronization
- Processes एक-दूसरे को affect करते हैं
- एक process का output दूसरे का input होता है
👉 Synchronization न होने पर:
- Deadlock हो सकता है
Example (Linux)
- ps → running processes list देता है
- grep → specific process (chrome) find करता है
- wc → output count करता है
👉 यहाँ:
- ps → producer
- grep → intermediate
- wc → consumer
➡️ यह cooperative processes का example है
Conditions that Require Process Synchronization
1. Critical Section
- Code का वह हिस्सा जहाँ shared variables access होते हैं
- एक समय में केवल एक process allowed
👉 Goal: data consistency maintain करना
2. Race Condition
- जब result execution order पर depend करता है
- Multiple processes एक साथ critical section में access करते हैं
3. Pre-emption
- OS running process को रोककर दूसरे को CPU देता है
- Problem तब होती है जब process shared resource use करते समय interrupt हो जाए
👉 बिना synchronization के:
- दूसरा process गलत (inconsistent) data read कर सकता है
6. Critical section
Critical Section in Synchronization
Critical Section
Critical Section program का वह हिस्सा होता है जहाँ shared resources (जैसे memory, files, variables) को multiple processes/threads द्वारा access किया जाता है।
👉 Problems avoid करने के लिए:
- एक समय में केवल एक process/thread को ही critical section execute करना चाहिए
- इसके लिए synchronization techniques (जैसे mutex, semaphore) का उपयोग किया जाता है
👉 इससे:
- Race condition avoid होती है
- Data consistency maintain रहती है
- System safe और predictable बनता है
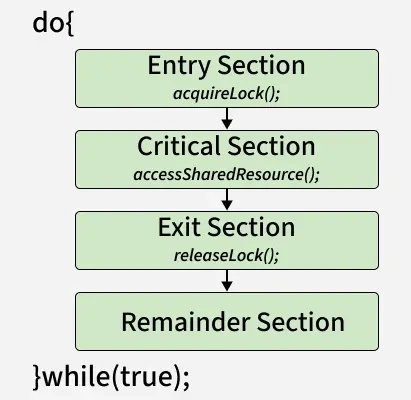
Structure of a Critical Section
1. Entry Section
- Process critical section में जाने की permission मांगता है
- यहाँ mutex या semaphore जैसे tools का उपयोग होता है
2. Critical Section
- यह actual code होता है
- जहाँ shared resources को access या modify किया जाता है
3. Exit Section
- Process critical section से बाहर निकलते समय lock release करता है
- ताकि अन्य processes अंदर आ सकें
4. Remainder Section
- Program का बाकी हिस्सा
- जहाँ shared resource access नहीं होता
आसान समझ (Simple Understanding)
👉 Flow कुछ इस तरह होता है:
Entry → Critical Section → Exit → Remainder
Critical Section Problem
Shared Resources और Race Condition
Shared resources में शामिल होते हैं:
- memory
- global variables
- files
- databases
👉 Race Condition तब होती है जब:
दो या अधिक processes एक ही समय पर shared data को update करते हैं, जिससे गलत result आता है।
📌 Example:
दो bank transactions एक साथ account balance update करें → final balance गलत हो सकता है
Pseudo Code (Simple समझ)
flag = 1;
while(flag); // entry section
// critical section
if (!flag)
// remainder section
} while(true);
Requirements of a Good Solution
एक अच्छा critical section solution में ये qualities होनी चाहिए:
- Correctness → data consistent रहे
- Efficiency → waiting कम हो, CPU utilization ज्यादा हो
- Fairness → कोई process unfairly wait न करे
3 Main Conditions (Very Important ⭐)
1. Mutual Exclusion
- एक समय में केवल एक process critical section में जाए
- Conflicts को prevent करता है
2. Progress
- अगर कोई process critical section में नहीं है, तो next process को entry मिलनी चाहिए
- System idle या stuck नहीं होना चाहिए
3. Bounded Waiting
- हर process के wait करने का limit होना चाहिए
- किसी process को हमेशा के लिए wait (starvation) नहीं होना चाहिए
Simple Solution (Lock Concept)
// Critical Section
releaseLock();
👉
- Process पहले lock acquire करता है
- Critical section execute करता है
- फिर lock release करता है
Real-Life Examples of Critical Section
1. Banking System (ATM / Online Banking)
- Critical Section: account balance update
- ❌ Problem: simultaneous withdrawal → wrong balance
2. Ticket Booking System
- Critical Section: last seat booking
- ❌ Problem: दो users एक ही seat book कर सकते हैं
3. Print Spooler
- Critical Section: print queue access
- ❌ Problem: print jobs mix या skip हो सकते हैं
4. Shared File Editing (Google Docs, MS Word)
- Critical Section: file save/write
- ❌ Problem: data conflict या data loss
7. Deadlock
Introduction of Deadlock in Operating System
Deadlock in Operating System
Deadlock एक ऐसी स्थिति है जिसमें दो या अधिक processes हमेशा के लिए stuck हो जाते हैं क्योंकि हर process दूसरे के resource का wait कर रहा होता है।
👉 Deadlock तब होता है जब ये 4 conditions एक साथ मौजूद हों:
- Mutual Exclusion
- Hold and Wait
- No Preemption
- Circular Wait
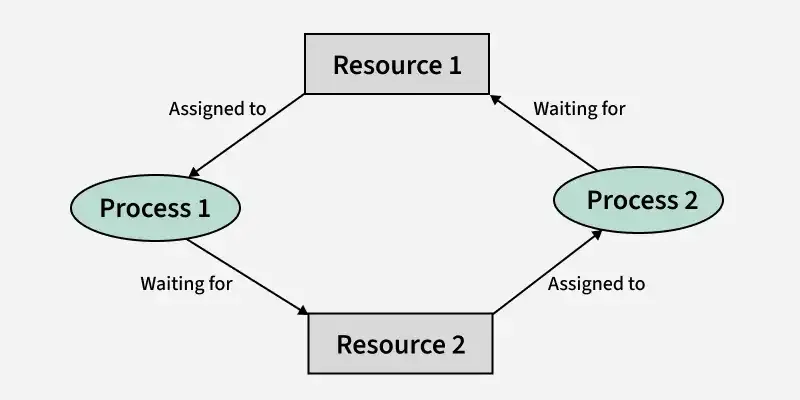
Simple Example
- P1 के पास R1 है और उसे R2 चाहिए
- P2 के पास R2 है और उसे R1 चाहिए
👉 Result:
दोनों process एक-दूसरे का wait करते रहते हैं → Deadlock
How Deadlock Occurs in OS
एक process resources को इस sequence में use करता है:
- Request a resource
- Use the resource
- Release the resource
👉 Deadlock तब होता है जब:
- Process कुछ resources hold करता है
- और दूसरे resources का wait करता है
Example (Step-wise)
- Process P1 holds R1 और R2 request करता है
- Process P2 holds R2 और R1 request करता है
👉 दोनों processes आगे नहीं बढ़ सकते → system deadlock में चला जाता है
Deadlock Handling Methods
1. Prevention
- Deadlock की conditions को होने से पहले ही रोकना
2. Avoidance
- System safe state maintain करता है
- Example: Banker’s Algorithm
3. Detection and Recovery
- Deadlock detect किया जाता है
- फिर processes को terminate या resources release करके recover किया जाता है
Examples of Deadlock
1. Tape Drive Example
- System में 2 tape drives हैं
- P0 और P1 दोनों के पास एक-एक tape drive है
- दोनों को दूसरा tape drive भी चाहिए
👉 Result:
दोनों process wait करते रहते हैं → Deadlock
2. Semaphore Example
Semaphores A और B की initial value = 1
| P0 Action | P1 Action |
|---|---|
| wait(A) | wait(B) |
| wait(B) | wait(A) |
👉
- P0 ने A ले लिया, अब B का wait कर रहा है
- P1 ने B ले लिया, अब A का wait कर रहा है
➡️ दोनों stuck → Deadlock
3. Memory Allocation Example
Total memory = 200KB
- P0 request: 80KB → मिल गया
- P1 request: 70KB → मिल गया
- P0 request: 60KB → wait
- P1 request: 80KB → wait
👉
दोनों processes अपने पास memory hold किए हुए हैं और extra memory का wait कर रहे हैं
➡️ Result: Deadlock
Necessary Conditions for Deadlock ⭐
Deadlock तभी होता है जब ये चारों conditions एक साथ मौजूद हों:
1. Mutual Exclusion
- एक resource एक समय में केवल एक process use कर सकता है
- Resource non-sharable होता है
2. Hold and Wait
- Process एक resource hold करता है
- और दूसरे resource का wait करता है
3. No Preemption
- Resource को process से forcefully वापस नहीं लिया जा सकता
- Process खुद release करेगा
4. Circular Wait
- Processes एक circular chain में एक-दूसरे का wait करते हैं
👉 Example:
P1 → P2 → P3 → P4 → फिर P1

ऊपर दिया गया circular wait deadlock इस प्रकार समझा जा सकता है:
- P1 के पास R1 resource है और वह R2 का wait कर रहा है (जो P2 के पास है)।
- P2 के पास R2 resource है और वह R3 का wait कर रहा है (जो P3 के पास है)।
- P3 के पास R3 resource है और वह R4 का wait कर रहा है (जो P4 के पास है)।
- P4 के पास R4 resource है और वह R1 का wait कर रहा है (जो P1 के पास है)।
8. Condition
Operating System Tutorial
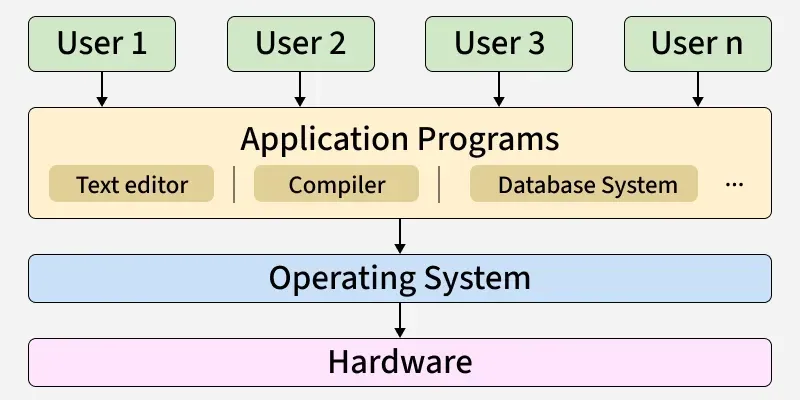
Operating System (OS) एक software होता है जो computer के hardware और software resources को manage और handle करता है।
- Computer के resources जैसे CPU, memory, files को manage करता है
- User और hardware के बीच interface का काम करता है
- Core functions जैसे process management, memory management, file management perform करता है
- System resources को government के अलग-अलग departments की तरह organize करता है
Examples (उदाहरण):
Linux, Unix, Windows 11, MS-DOS, Android, macOS, iOS
Basics (मूल बातें)
यह section Operating System के basic concepts को introduce करता है।
- Introduction (परिचय)
- Types of OS (OS के प्रकार)
- Kernel in OS (OS में kernel)
- System Call (system call)
- System Initialization (system initialization)
Process Scheduling (प्रोसेस शेड्यूलिंग)
यह section process management और scheduling पर focus करता है।
- Process Introduction (प्रोसेस परिचय)
- Process Control Block (PCB)
- Process Table (प्रोसेस टेबल)
- Process Management Introduction (प्रोसेस मैनेजमेंट)
- Process States (प्रोसेस की अवस्थाएं)
- Process Scheduler (प्रोसेस scheduler)
- CPU Scheduling Algorithms (CPU scheduling algorithms)
- Preemptive vs Non-Preemptive
- Dispatcher vs Scheduler
- Starvation and Aging
- Quiz: CPU Scheduling
Process Synchronization (प्रोसेस सिंक्रोनाइजेशन)
यह section synchronization और IPC concepts को cover करता है।
- Inter Process Communication (IPC)
- Process Synchronization
- Race Condition
- Critical Section
- Solutions to Synchronization Problems
- Peterson’s Algorithm
- Dekker’s Algorithm
- Bakery Algorithm
- Hardware Based Solutions
- Semaphores
- Mutex vs Semaphore
- Monitors
- Priority Inversion
- Classical IPC Problems
- Quiz: Process Synchronization
Deadlock (डेडलॉक)
यह section OS में deadlock को explain करता है।
- Introduction (परिचय)
- Deadlock Handling
- Deadlock Prevention
- Banker’s Algorithm (Deadlock Avoidance)
- Detection and Recovery
- Starvation और Livelock
- Resource Allocation Graph (RAG)
- Methods of Resource Allocation
- Deadlock-free condition program
- Quiz: Deadlock
Multithreading (मल्टीथ्रेडिंग)
यह section multithreading concepts को समझाता है।
- Thread in Operating System
- User Level vs Kernel Level Threads
- Process-based vs Thread-based Multitasking
- Multithreading Models
- Benefits of Multithreading
- Quiz: Multithreading
Memory Management (मेमोरी मैनेजमेंट)
1. Basics (मूल बातें)
- Memory introduction और units
- Memory Management in OS
- Logical vs Physical Address
2. Contiguous Allocation
- Implementation of Contiguous Memory
- Internal Fragmentation
- External Fragmentation
- Next Fit Algorithm
- Buddy System
3. Non-Contiguous Allocation
- Paging
- Page Table Entries
- Segmentation
- Segmentation with Paging
4. Advanced Concepts
- Overlays
- Virtual Memory
- Demand Paging
- Page Fault Handling
- Swap Space
5. Page Replacement & Thrashing
- Page Replacement Algorithms
- Belady’s Anomaly
- Second Chance Algorithm
- Thrashing Handling Techniques
- Working Set
6. Kernel & System Concepts
- Kernel Memory Allocation
- Memory Interleaving
- Virtualization
- Quiz: Memory Management
Disk Management (डिस्क मैनेजमेंट)
यह section disk और file management को explain करता है।
- File Systems
- Unix File System
- File Directory & Path Name
- Directory Structure
- File Allocation Methods
- File Access Methods
- Secondary Memory
- Hard Disk Drive
- Disk Scheduling Algorithms
- SSTF Algorithm Program
- Spooling क्या है
- Spooling vs Buffering
- Free Space Management
- Quiz: Input Output Systems